Ressources
Logiciels
AGORA
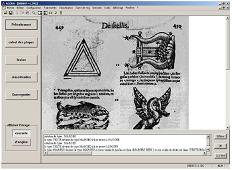 Le logiciel AGORA permet d'extraire des méta-données
des images de documents historiques en fonction
d'un scénario défini par l'utilisateur.
Pour cela, AGORA repose sur l'analyse de deux cartes de segmentation en blocs de l'image :
une des formes et l'autre du fond.
AGORA procčde alors ŕ une classification des blocs extraits
pour la constitution des méta-données.
Cette classification opčre selon un
scénario produit par l'utilisateur
au cours d'une phase d'interaction avec AGORA.
Le logiciel AGORA permet d'extraire des méta-données
des images de documents historiques en fonction
d'un scénario défini par l'utilisateur.
Pour cela, AGORA repose sur l'analyse de deux cartes de segmentation en blocs de l'image :
une des formes et l'autre du fond.
AGORA procčde alors ŕ une classification des blocs extraits
pour la constitution des méta-données.
Cette classification opčre selon un
scénario produit par l'utilisateur
au cours d'une phase d'interaction avec AGORA.
DEBORA
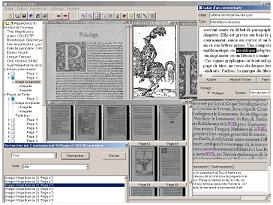 DEBORA propose des méthodes d’analyse et
d’interprétation du contenu des images pour ŕ la fois réaliser une compression plus efficace
et extraire automatiquement des méta-données utiles ŕ l’indexation par le contenu. Pour cela
DEBORA est basée sur une décomposition des images en objets indépendants qui seront
compressés avec des méthodes appropriées. DEBORA propose aussi un format de données
hétérogčnes, adapté ŕ la navigation dans les ouvrages numérisés compressés, qui permet
aussi de les modifier, les annoter ou les échanger sur Internet dans le cadre d’un travail
collaboratif.
DEBORA propose des méthodes d’analyse et
d’interprétation du contenu des images pour ŕ la fois réaliser une compression plus efficace
et extraire automatiquement des méta-données utiles ŕ l’indexation par le contenu. Pour cela
DEBORA est basée sur une décomposition des images en objets indépendants qui seront
compressés avec des méthodes appropriées. DEBORA propose aussi un format de données
hétérogčnes, adapté ŕ la navigation dans les ouvrages numérisés compressés, qui permet
aussi de les modifier, les annoter ou les échanger sur Internet dans le cadre d’un travail
collaboratif.
DOCREAD
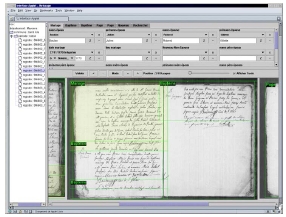 DocRead est un générateur automatique de systčmes de reconnaissance
de documents structurés. Il est constitué
d'un compilateur du langage EPF (permettant de décrire un document ŕ l'aide d'une grammaire),
d'un module d'analyse lié ŕ ce langage, d'un module de vision précoce
(binarisation et extraction de segments) et d'un classifieur ayant des capacités de rejet.
DocRead permet ainsi une adaptation rapide ŕ un nouveau type de document. En effet,
il faut simplement définir une nouvelle grammaire (ŕ l'aide d'EPF) qui décrit
le nouveau type de document.
DocRead est un générateur automatique de systčmes de reconnaissance
de documents structurés. Il est constitué
d'un compilateur du langage EPF (permettant de décrire un document ŕ l'aide d'une grammaire),
d'un module d'analyse lié ŕ ce langage, d'un module de vision précoce
(binarisation et extraction de segments) et d'un classifieur ayant des capacités de rejet.
DocRead permet ainsi une adaptation rapide ŕ un nouveau type de document. En effet,
il faut simplement définir une nouvelle grammaire (ŕ l'aide d'EPF) qui décrit
le nouveau type de document.
EMMA
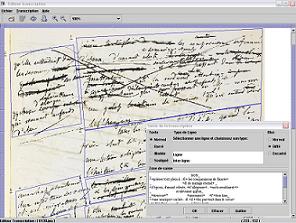 L'éditeur EMMA permet de réaliser des transcriptions dites "diplomatiques"
d'images de manuscrits. Son principal intéręt est de décharger le transcripteur
des problčmes fastidieux de mise en forme des transcriptions.
La sauvegarde des données s'effectue
dans un format XML baptisé Gustave_ML. Ce dernier facilite les échanges de données
en permettant l'enregistrement des transcriptions
dans différents formats tel que le HTML
pour la publication Web et le PDF pour l’impréssion papier.
L'éditeur EMMA permet de réaliser des transcriptions dites "diplomatiques"
d'images de manuscrits. Son principal intéręt est de décharger le transcripteur
des problčmes fastidieux de mise en forme des transcriptions.
La sauvegarde des données s'effectue
dans un format XML baptisé Gustave_ML. Ce dernier facilite les échanges de données
en permettant l'enregistrement des transcriptions
dans différents formats tel que le HTML
pour la publication Web et le PDF pour l’impréssion papier.
QUEID
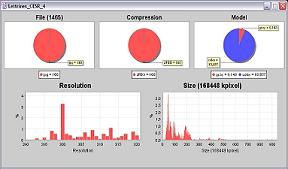 QUEID "QUery Engine on Image Databases" est un outil de diagnostic
de base d'images numérisées. Il extrait des bases
les caractéristiques des images (modčles, formats, résolutions, etc.)
afin d'en dresser une analyse statistique présentée
sous la forme de graphiques ŕ l'utilisateur.
Ce dernier peut dans une deuxičme étape utiliser QUEID en mode requęte
sur les caractéristiques des images. Le but est de naviguer
au sein des bases afin d'identifier les éventuels problčmes de numérisation.
QUEID "QUery Engine on Image Databases" est un outil de diagnostic
de base d'images numérisées. Il extrait des bases
les caractéristiques des images (modčles, formats, résolutions, etc.)
afin d'en dresser une analyse statistique présentée
sous la forme de graphiques ŕ l'utilisateur.
Ce dernier peut dans une deuxičme étape utiliser QUEID en mode requęte
sur les caractéristiques des images. Le but est de naviguer
au sein des bases afin d'identifier les éventuels problčmes de numérisation.
REIRE
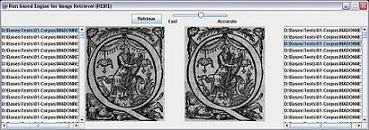 REIRE "Run Encoding Image based Retrieval Engine" est un moteur de recherche
d'images similaires. Le but de REIRE est le traitement rapide de larges bases.
Pour ce faire REIRE exploite une représentation compressée des images ŕ base de plages.
Cette représentation est utilisée ŕ différents niveaux au travers d’un mécanisme
de recherche perceptif. La recherche est alors affinée successivement afin de limiter
l’espace de comparaison. Cette approche permet ŕ REIRE d’effectuer des recherches
particuličrement rapides des images au sein de larges bases.
REIRE "Run Encoding Image based Retrieval Engine" est un moteur de recherche
d'images similaires. Le but de REIRE est le traitement rapide de larges bases.
Pour ce faire REIRE exploite une représentation compressée des images ŕ base de plages.
Cette représentation est utilisée ŕ différents niveaux au travers d’un mécanisme
de recherche perceptif. La recherche est alors affinée successivement afin de limiter
l’espace de comparaison. Cette approche permet ŕ REIRE d’effectuer des recherches
particuličrement rapides des images au sein de larges bases.
Bases d'images
Des base d'images graphiques (lettrines, marques typographiques, portraits, ...) des BVH sont mises ŕ disposition sur la page suivante.
Une base experimentale d'impréssions anciennes constituée durant la Thčse de E. Baudrier est disponible ŕ l'adresse suivante.